This tutorial explains how to read a CSV file in python using the read_csv function from the pandas library. Without using the read_csv function, it can be tricky to import a CSV file into your Python environment.
Syntax : read_csv() Function
The basic syntax for importing a CSV file using read_csv is as follows:
import pandas as pd
mydata = pd.read_csv("file.csv")In the above function, you just need to specify the filename with the complete file location. It assumes you have column names in the first row of your CSV file.
Note – First check if pandas package is installed on your system. If it is not installed, you can install it by using the command pip install pandas.
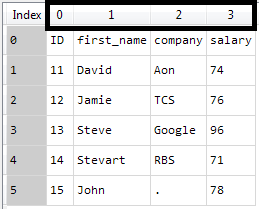
You can download the sample data for understanding examples by clicking the link below and then right-click and choose the Save as option to download it.
The sample data looks like below –
ID first_name company salary
0 11 David Aon 74
1 12 Jamie TCS 76
2 13 Steve Google 96
3 14 Stevart RBS 71
4 15 John . 78
Example 1 : Read CSV file with header row
While specifying the full file location, use either forward slash (/) or double backward slashes (\\). Single backward slash does not work in Python because it is treated as an escape character in Python strings.
import pandas as pd
mydata = pd.read_csv("file.csv")It is important to note that header=0 is the default value. Hence we don’t need to mention the header= parameter. It means header starts from first row as indexing in python starts from 0.
Inspect data after importing
mydata.shape
mydata.columns
mydata.dtypes
It returns 5 number of rows and 4 number of columns. Column Names are ['ID', 'first_name', 'company', 'salary']
See the column types of data we imported. first_name and company are character variables. Remaining variables are numeric ones.
ID int64
first_name object
company object
salary int64
Example 2 : Read CSV file with header in second row
Suppose you have column or variable names in second row. To read this kind of CSV file, you can submit the following command.
import pandas as pd
mydata = pd.read_csv("file.csv", header = 1)header=1 tells python to pick header from second row. It’s setting second row as header. It’s not a realistic example. I just used it for illustration so that you get an idea how to solve it. To make it practical, you can add random values in first row in CSV file and then import it again.
11 David Aon 74
0 12 Jamie TCS 76
1 13 Steve Google 96
2 14 Stevart RBS 71
3 15 John . 78
Define your own column names instead of header row from CSV file
import pandas as pd
mydata0 = pd.read_csv("file.csv", skiprows=1, names=['CustID', 'Name', 'Companies', 'Income'])skiprows = 1 means we are ignoring first row and names= option is used to assign variable names manually.
CustID Name Companies Income
0 11 David Aon 74
1 12 Jamie TCS 76
2 13 Steve Google 96
3 14 Stevart RBS 71
4 15 John . 78
Example 3 : Skip rows but keep header
import pandas as pd
mydata = pd.read_csv("file.csv", skiprows=[1,2])In this case, we are skipping second and third rows while importing. Don’t forget index starts from 0 in python so 0 refers to first row and 1 refers to second row and 2 implies third row.
ID first_name company salary
0 13 Steve Google 96
1 14 Stevart RBS 71
2 15 John . 78
Instead of [1,2] you can also write range(1,3). Both means the same thing but range( ) function is very useful when you want to skip many rows so it saves time of manually defining row position.
When skiprows = 4, it means skipping four rows from top. skiprows=[1,2,3,4] means skipping rows from second through fifth. It is because when list is specified in skiprows= option, it skips rows at index positions. When a single integer value is specified in the option, it considers skip those rows from top.
Example 4 : Read CSV file without header row
If you specify “header = None”, python would assign a series of numbers starting from 0 to (number of columns – 1) as column names. In this datafile, we have column names in first row.
import pandas as pd
mydata0 = pd.read_csv("file.csv", header = None)See the output shown below-
Add prefix to column names
import pandas as pd
>mydata0 = pd.read_csv("file.csv", header = None, prefix="var")In this case, we are setting var as prefix which tells python to include this keyword before each column name.
var0 var1 var2 var3
0 ID first_name company salary
1 11 David Aon 74
2 12 Jamie TCS 76
3 13 Steve Google 96
4 14 Stevart RBS 71
5 15 John . 78
Example 5 : Specify missing values
The na_values= options is used to set some values as blank / missing values while importing CSV file.
import pandas as pd
mydata00 = pd.read_csv("file.csv", na_values=['.'])Output
ID first_name company salary
0 11 David Aon 74
1 12 Jamie TCS 76
2 13 Steve Google 96
3 14 Stevart RBS 71
4 15 JohnNaN 78
Example 6 : Set Index Column
import pandas as pd
mydata01 = pd.read_csv("file.csv", index_col ='ID')Output
first_name company salary
ID
11 David Aon 74
12 Jamie TCS 76
13 Steve Google 96
14 Stevart RBS 71
15 John . 78
As you can see in the above output, the column ID has been set as index column.
Example 7 : Read CSV File from External URL
You can directly read data from the CSV file that is stored on a web link. It is very handy when you need to load publicly available datasets from github, kaggle and other websites.
import pandas as pd
mydata02 = pd.read_csv("<https://domain.com/file.csv>")This DataFrame contains 2311 rows and 8 columns. Using mydata02.shape, you can generate this summary.
Example 8 : Skip Last N Rows While Importing CSV
import pandas as pd
mydata04 = pd.read_csv("<https://domain.com/file.csv>", skipfooter=2)In the above code, we are excluding the bottom 2 rows using skipfooter parameter.
Example 9 : Read only first N rows
import pandas as pd
mydata05 = pd.read_csv("<https://domain.com/file.csv>", nrows=3)Using nrows= option, you can load top N number of rows.
Example 10 : Interpreting “,” as thousands separator
import pandas as pd
mydata06 = pd.read_csv("<https://domain.com/file.csv>", thousands=",")Example 11 : Read only specific columns
import pandas as pd
mydata07 = pd.read_csv("<https://domain.com/file.csv>", usecols=[1,3])The above code reads only second and fourth columns based on index positions.
Example 12 : Read some rows and columns
import pandas as pd
mydata08 = pd.read_csv("<https://domain.com/file.csv>", usecols=[1,3], nrows=3)In the above command, we have combined usecols= and nrows= options. It will select only first 3 rows from second and fourth columns.
Example 13 : Read file with semi colon delimiter
import pandas as pd
mydata09 = pd.read_csv("file_path", sep = ';')Using sep= parameter in read_csv( ) function, you can import file with any delimiter other than default comma. In this case, we are using semi-colon as a separator.
Example 14 : Change column type while importing CSV
Suppose you want to change column format from int64 to float64 while loading CSV file into Python. We can use dtype = option for the same.
import pandas as pd
mydf = pd.read_csv("file.csv", dtype = {"salary" : "float64"})Example 15 : Measure time taken to import big CSV file
With the use of verbose=True, you can capture time taken for Tokenization, conversion and Parser memory cleanup.
import pandas as pdmydf = pd.read_csv("file.csv", verbose=True)